앞의 11장에서는 1과 0으로 나타낼 수 있는 이중 분류를 통해 데이터 분석을 진행했다.
하지만, 참과 거짓으로 모든 데이터를 정의내릴 수 없다.
그러므로 class가 3개 이상이 되는(ex. 노란색, 파란색, 초록색) 다중 분류 문제를 원-핫 인코딩법 그리고 소프트맥스를 적용해 해결해보는 법을 공부했다.

총 두 가지 실습을 진행했다.
1) 아이리스 꽃 분류
In [4]:
# 라이브러리 설치
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.preprocessing import LabelEncoder
In [5]:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
In [6]:
#seed 값 설정
np.random.seed(3)
tf.random.set_seed(3)
In [7]:
#데이터 입력
df = pd.read_csv("dataset/iris.csv",names=["sepal_length","sepal_width","petal_length","petal_width","species"])
In [8]:
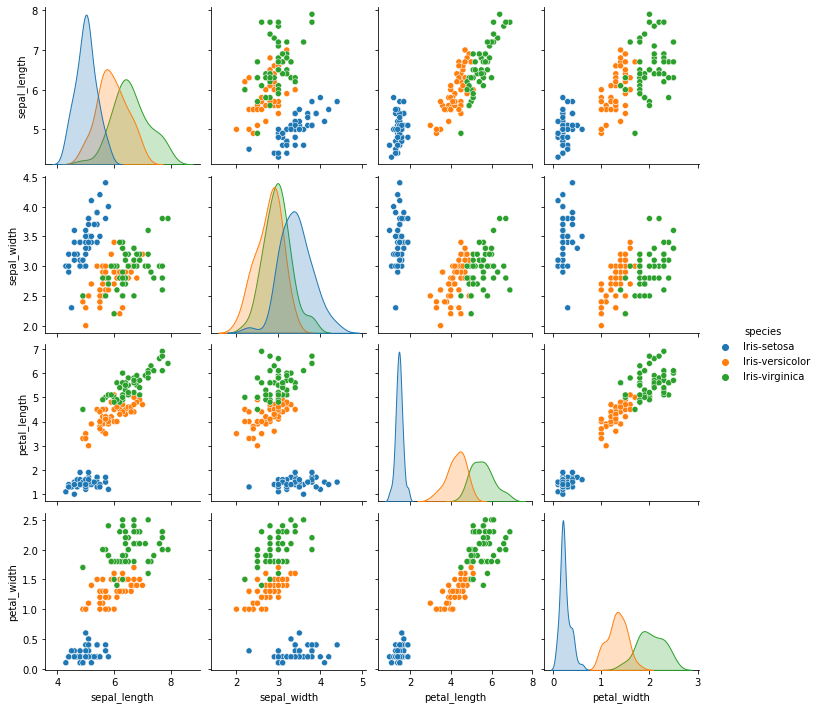
# 그래프로 확인
sns.pairplot(df,hue='species'); #pairplot() 데이터 전체를 한번에 보는그래프
plt.show()
In [9]:
# 데이터 분류
dataset = df.values
X = dataset[:,0:4].astype(float)
Y_obj = dataset[:,4]
# 문자열을 숫자로 변환
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj)
# 원-핫 인코딩
Y_encoded = tf.keras.utils.to_categorical(Y)
# 모델의 설정
model = Sequential()
model.add(Dense(16, input_dim=4, activation='relu'))
model.add(Dense(3, activation='softmax')) # 소프트맥스
# 모델 컴파일
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 모델 실행
model.fit(X, Y_encoded, epochs=50, batch_size=1)
# 결과 출력
print("\n Accuracy: %.4f" % (model.evaluate(X, Y_encoded)[1]))
Epoch 1/50
150/150 [==============================] - 1s 1ms/step - loss: 1.3259 - accuracy: 0.3333
Epoch 2/50
150/150 [==============================] - 0s 2ms/step - loss: 0.8409 - accuracy: 0.6333
Epoch 3/50
150/150 [==============================] - 0s 1ms/step - loss: 0.7110 - accuracy: 0.7267
Epoch 4/50
150/150 [==============================] - 0s 2ms/step - loss: 0.6229 - accuracy: 0.6867
Epoch 5/50
150/150 [==============================] - 0s 2ms/step - loss: 0.5542 - accuracy: 0.7933
Epoch 6/50
150/150 [==============================] - 0s 1ms/step - loss: 0.4988 - accuracy: 0.9067
Epoch 7/50
150/150 [==============================] - 0s 1ms/step - loss: 0.4562 - accuracy: 0.9133
Epoch 8/50
150/150 [==============================] - 0s 1ms/step - loss: 0.4287 - accuracy: 0.9067
Epoch 9/50
150/150 [==============================] - 0s 2ms/step - loss: 0.4006 - accuracy: 0.9267
Epoch 10/50
150/150 [==============================] - 0s 1ms/step - loss: 0.3773 - accuracy: 0.9733
Epoch 11/50
150/150 [==============================] - 0s 1ms/step - loss: 0.3569 - accuracy: 0.9267
Epoch 12/50
150/150 [==============================] - 0s 2ms/step - loss: 0.3367 - accuracy: 0.9333
Epoch 13/50
150/150 [==============================] - 0s 1ms/step - loss: 0.3272 - accuracy: 0.9600
Epoch 14/50
150/150 [==============================] - 0s 1ms/step - loss: 0.3060 - accuracy: 0.9667
Epoch 15/50
150/150 [==============================] - 0s 1ms/step - loss: 0.2920 - accuracy: 0.9667
Epoch 16/50
150/150 [==============================] - 0s 1ms/step - loss: 0.2784 - accuracy: 0.9600
Epoch 17/50
150/150 [==============================] - 0s 1ms/step - loss: 0.2697 - accuracy: 0.9600
Epoch 18/50
150/150 [==============================] - 0s 1ms/step - loss: 0.2639 - accuracy: 0.9533
Epoch 19/50
150/150 [==============================] - 0s 1ms/step - loss: 0.2473 - accuracy: 0.9733
Epoch 20/50
150/150 [==============================] - 0s 1ms/step - loss: 0.2359 - accuracy: 0.9733
Epoch 21/50
150/150 [==============================] - 0s 1ms/step - loss: 0.2274 - accuracy: 0.9733
Epoch 22/50
150/150 [==============================] - 0s 1ms/step - loss: 0.2225 - accuracy: 0.9733
Epoch 23/50
150/150 [==============================] - 0s 1ms/step - loss: 0.2106 - accuracy: 0.9733
Epoch 24/50
150/150 [==============================] - 0s 1ms/step - loss: 0.2062 - accuracy: 0.9667
Epoch 25/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1939 - accuracy: 0.9800
Epoch 26/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1896 - accuracy: 0.9733
Epoch 27/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1832 - accuracy: 0.9667
Epoch 28/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1683 - accuracy: 0.9800
Epoch 29/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1714 - accuracy: 0.9667
Epoch 30/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1693 - accuracy: 0.9667
Epoch 31/50
150/150 [==============================] - 0s 2ms/step - loss: 0.1619 - accuracy: 0.9733
Epoch 32/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1555 - accuracy: 0.9667
Epoch 33/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1515 - accuracy: 0.9800
Epoch 34/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1458 - accuracy: 0.9667
Epoch 35/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1427 - accuracy: 0.9733
Epoch 36/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1421 - accuracy: 0.9667
Epoch 37/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1321 - accuracy: 0.9667
Epoch 38/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1348 - accuracy: 0.9667
Epoch 39/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1274 - accuracy: 0.9800
Epoch 40/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1313 - accuracy: 0.9667
Epoch 41/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1227 - accuracy: 0.9733
Epoch 42/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1212 - accuracy: 0.9733
Epoch 43/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1201 - accuracy: 0.9800
Epoch 44/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1156 - accuracy: 0.9667
Epoch 45/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1205 - accuracy: 0.9600
Epoch 46/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1142 - accuracy: 0.9667
Epoch 47/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1148 - accuracy: 0.9667
Epoch 48/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1099 - accuracy: 0.9667
Epoch 49/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1084 - accuracy: 0.9667
Epoch 50/50
150/150 [==============================] - 0s 1ms/step - loss: 0.1112 - accuracy: 0.9533
5/5 [==============================] - 0s 3ms/step - loss: 0.1024 - accuracy: 0.9733
Accuracy: 0.9733
2) MNIST 손글씨 분류
파이토치를 이용한 MNIST 손글씨 분류하기
pytorch documentation : https://pytorch.org/docs/stable/index.html
In [1]:
import torch
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import matplotlib.pyplot as plt
import random
GPU 사용설정
런타임 > 런타임 유형 변경 > GPU
In [2]:
USE_CUDA = torch.cuda.is_available() # GPU를 사용가능하면 True, 아니라면 False를 리턴
device = torch.device("cuda" if USE_CUDA else "cpu") # GPU 사용 가능하면 사용하고 아니면 CPU 사용
print(device)
cuda
In [3]:
# 시드 고정 => 성능
random.seed(777)
torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777)
In [4]:
# 하이퍼 파라미터 설정
training_epochs = 15 #학습의 횟수
batch_size = 100 #모델의 가중치를 한번 업데이트시킬 때 사용되는 샘플들의 묶음
#만약 1000개의 훈련 샘플이 존재할 때, 에포크가 15이고 배치 사이즈가 100이면, 가중치를 10번 업데이트하는 것을 총 15번 반복하는 것
데이터 불러오기
In [6]:
# MNIST 데이터셋
#트레인셋
mnist_train = dsets.MNIST(root='MNIST_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
#테스트셋 직접 코드 짜봅시다!
#힌트 : 훈련 여부, 텐서 형태로 변환 여부, 다운로드 여부
mnist_test = dsets.MNIST(root='MNIST_data/',
train=False,
transform=transforms.ToTensor(),
download=True
)
In [8]:
# data loader
data_loader = DataLoader(dataset=mnist_train,
batch_size=batch_size, # 배치 크기는 100
shuffle=True,
drop_last=True)
모델설계
torch.nn.Linear(in_features,out_features,bias = True, device = None,dtype = None)
In [9]:
# 이미지 크기 28*28
linear = nn.Linear(28*28,10,bias=True).to(device)
In [11]:
# 비용 함수
# 내부적으로 소프트맥스 함수를 계산하고 있음.
criterion = nn.CrossEntropyLoss().to(device)
#옵티마이저
#SGD(확률적 경사하강법)사용, 학습률 0.1
optimizer = torch.optim.SGD(linear.parameters(),lr=0.1)
모델학습
In [12]:
# 여기서 모르는 코드는 pytorch documentation에서 찾아보고 주석처리를 해보시는 것을 추천합니다.
for epoch in range(training_epochs):
avg_cost = 0
total_batch = len(data_loader)
for X, Y in data_loader:
X = X.view(-1, 28 * 28).to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = linear(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost))
print('Learning finished')
Epoch: 0001 cost = 0.535150647
Epoch: 0002 cost = 0.359577745
Epoch: 0003 cost = 0.331264257
Epoch: 0004 cost = 0.316404670
Epoch: 0005 cost = 0.307106972
Epoch: 0006 cost = 0.300456583
Epoch: 0007 cost = 0.294933438
Epoch: 0008 cost = 0.290956229
Epoch: 0009 cost = 0.287074089
Epoch: 0010 cost = 0.284515619
Epoch: 0011 cost = 0.281914085
Epoch: 0012 cost = 0.279526889
Epoch: 0013 cost = 0.277636617
Epoch: 0014 cost = 0.275874794
Epoch: 0015 cost = 0.274422735
Learning finished
모델 테스트하기
In [13]:
# 모델 테스트
with torch.no_grad(): # torch.no_grad()를 하면 gradient 계산을 수행하지 않는다.
X_test = mnist_test.test_data.view(-1, 28 * 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = linear(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print('Accuracy:', accuracy.item())
# 무작위 데이터 예측
r = random.randint(0, len(mnist_test) - 1)
X_single_data = mnist_test.test_data[r:r + 1].view(-1, 28 * 28).float().to(device)
Y_single_data = mnist_test.test_labels[r:r + 1].to(device)
print('Label: ', Y_single_data.item())
single_prediction = linear(X_single_data)
print('Prediction: ', torch.argmax(single_prediction, 1).item())
plt.imshow(mnist_test.test_data[r:r + 1].view(28, 28), cmap='Greys', interpolation='nearest')
plt.show()
/usr/local/lib/python3.7/dist-packages/torchvision/datasets/mnist.py:67: UserWarning: test_data has been renamed data
warnings.warn("test_data has been renamed data")
/usr/local/lib/python3.7/dist-packages/torchvision/datasets/mnist.py:57: UserWarning: test_labels has been renamed targets
warnings.warn("test_labels has been renamed targets")
Accuracy: 0.8883000016212463
Label: 8
Prediction: 3

In [ ]:
'AI & Data Analysis > 인공지능 스터디' 카테고리의 다른 글
| [모두의 딥러닝] #11장: 데이터 다루기 (0) | 2022.01.25 |
|---|---|
| [모두의 딥러닝] #10장: 모델 설계하기 (0) | 2022.01.25 |
| [모두의 딥러닝] #9장: 신경망에서 딥러닝으로 (0) | 2022.01.22 |
| [모두의 딥러닝] #8장: 오차는 다운! 정확도는 업! 오차역전파 (1) | 2022.01.22 |
| [모두의 딥러닝] #7장: XOR 문제의 극복, 다층 퍼셉트론 (0) | 2022.01.22 |



